Hadoop-3.4.2集群化部署
本次实验采用三节点,主节点部署 NameNode + ResourceManager 纯管理(不运行DataNode/NodeManager),从节点部署 DataNode + NodeManger
一、环境准备
-
主机规划
主机名 IP地址 角色 Master 10.0.0.10 NameNode、ResourceManager、SecondaryNameNode Slave1 10.0.0.20 DataNode、NodeManager Slave2 10.0.0.30 DataNode、NodeManager -
软件依赖
-
创建hadoop用户
-
所有节点安装 Java11 环境
- 安装 Hadoop 3.4.2
- 配置 SSH 免密登录 ( master → 所有节点)
- 关闭防火墙或开放对应端口
-
二、基础配置 (所有节点)
-
创建用户
hadoop,并授权免密sudo创建用户
sudo useradd -m -s /bin/bash hadoop sudo passwd hadoop加入sudo组
usermod -aG sudo hadoopvisudo -f /etc/sudoers.d/hadoop # 输入以下内容 hadoop ALL=(ALL) NOPASSWD:ALLsu hadoop后续使用hadoop用户进行操作
-
安装 Java
使用apt安装
sudo apt install -y openjdk-11-jdk验证
$ java -version openjdk version "11.0.28" 2025-07-15 OpenJDK Runtime Environment (build 11.0.28+6-post-Ubuntu-1ubuntu125.04.1) OpenJDK 64-Bit Server VM (build 11.0.28+6-post-Ubuntu-1ubuntu125.04.1, mixed mode, sharing)通过find命令查找JAVA_HOME目录所在
$ find /usr/lib -name java /usr/lib/jvm/java-11-openjdk-amd64/bin/java设置JAVA_HOME
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> ~/.bashrc echo 'export PATH=$PATH:$JAVA_HOME/bin' >> ~/.bashrc加载文件生效
source ~/.bashrc -
下载并解压Hadoop
cd ~ wget https://archive.apache.org/dist/hadoop/core/hadoop-3.4.2/hadoop-3.4.2.tar.gz tar -zxvf hadoop-3.4.2.tar.gz mv hadoop-3.4.2 hadoop设置 Hadoop 环境变量(~/.bashrc)
vim ~/.bashrcexport HADOOP_HOME=/home/hadoop/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopsource ~/.bashrc
三、配置 SSH 免密登录(仅在 master 上操作)
确保/etc/hosts有正确的条目
$ cat /etc/hosts
10.0.0.10 master
10.0.0.20 slave1
10.0.0.30 slave2
在master节点执行
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id hadoop@master
ssh-copy-id hadoop@slave1
ssh-copy-id hadoop@slave2
测试ssh免密
ssh slave1
四、Hadoop 配置文件(在 master 节点上编辑)
进入 $HADOOP_HOME/etc/hadoop 目录,修改以下文件:
1. core-site.xml
vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
</property>
</configuration>
2. hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value> <!-- 根据 DataNode 数量调整 -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoop/hdfs/datanode</value>
</property>
</configuration>
3. yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
4. mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
5. workers(旧版为 slaves)
vim workers
slave1
slave2
6. hadoop-env.sh(修改JAVA_HOME)
sed -i "s|# export JAVA_HOME=.*|export JAVA_HOME=$JAVA_HOME|" "$HADOOP_CONF_DIR/hadoop-env.sh"
五、分发配置到其他节点
scp -r ~/hadoop hadoop@slave1:~/
scp -r ~/hadoop hadoop@slave2:~/
如果前面给从节点也上传了压缩包并解压了,则分发主要配置就行
for node in slave1 slave2; do
echo "Syncing config to $node..."
scp ~/hadoop/etc/hadoop/{core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml,workers} hadoop@$node:~/hadoop/etc/hadoop/
done
注意:在 slave1/slave2 上同样配置
.bashrc中的环境变量。$ tail -5 ~/.bashrc export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/home/hadoop/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
六、格式化 NameNode 并启动集群
1. 格式化 HDFS(仅首次)
hdfs namenode -format
2. 启动 HDFS
start-dfs.sh
3. 启动 YARN
start-yarn.sh
4. 验证进程
- master 上应有:NameNode、ResourceManager
- slave1/slave2 上应有:DataNode、NodeManager
使用 jps 命令查看。
Master
$ jps
1800 ResourceManager
1386 NameNode
2107 Jps
1597 SecondaryNameNode
Slave
$ jps
1568 Jps
1312 DataNode
1435 NodeManager
5. Web UI 访问
-
HDFS: http://master:9870
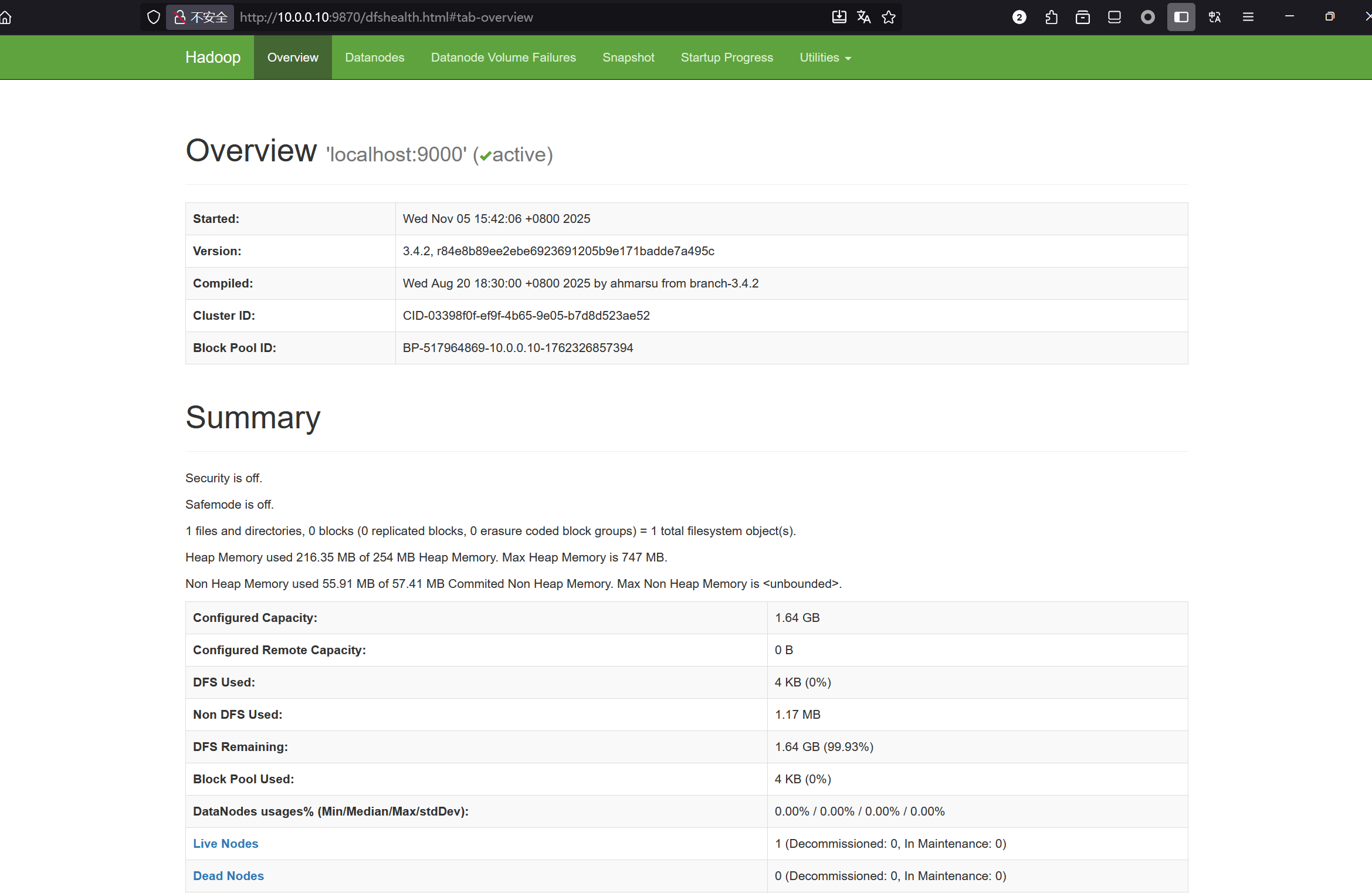
-
YARN: http://master:8088
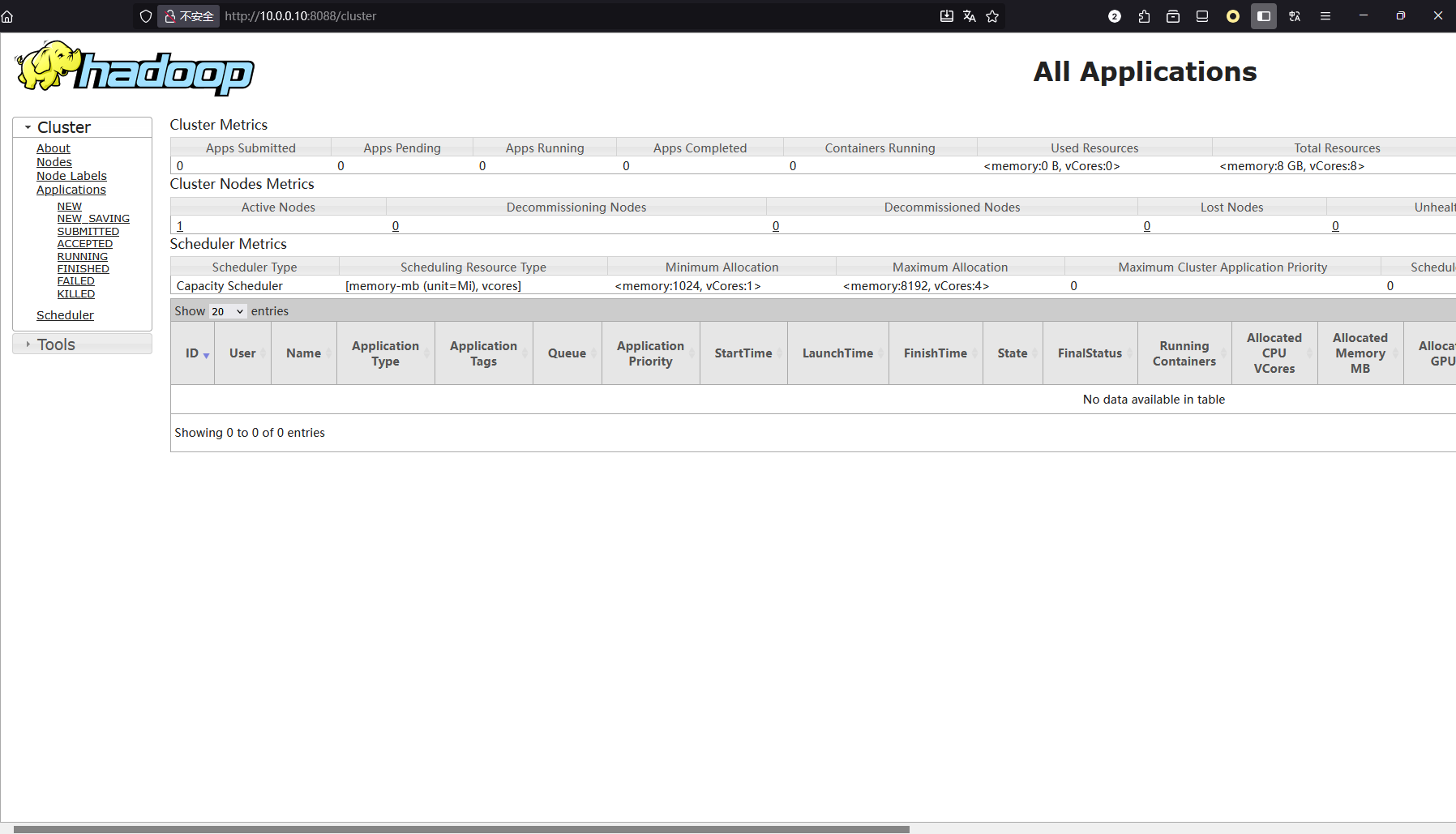
七、运行测试任务
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.4.2.jar pi 2 10